Integrating Asterisk with a database can add a great deal of functionality to your system. Additionally, it provides a way to build web-based configuration utilities to make the maintenance of an Asterisk system easier. What’s more, it allows instant access to information from the dialplan and other parts of the Asterisk system.
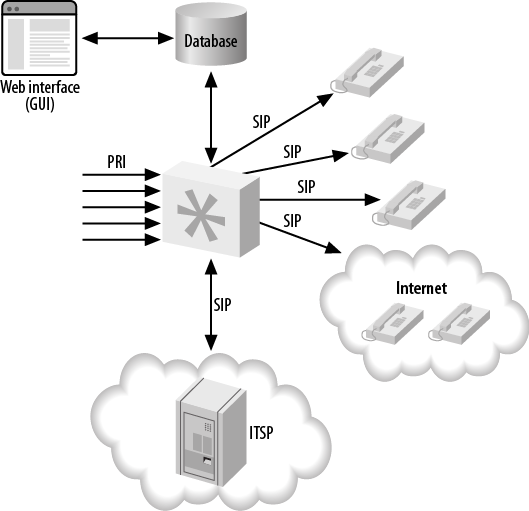
Adding database integration to Asterisk (Figure 22.4, “Asterisk database integration, single server”) is a powerful way of gaining access to information that can be manipulated by other means. For example, we can read information about the extensions and devices in the system from a database using the Asterisk Realtime Architecture (discussed in Chapter 16, Relational Database Integration), and we can modify the information stored in the database via an external system, such as a web page.
The integration with the database adds a layer between Asterisk and the web interface that the web designer is familiar with, and allows the manipulation of data in a way that doesn’t require any additional skill sets. Knowledge of Asterisk itself is left to the Asterisk administrator, and the web developer can happily work with tools she is familiar with.
Of course, this makes the Asterisk
system slightly more complex to build, but integration with a database
via ODBC adds all sorts of possibilities (such as hot-desking, discussed
in the section called “Getting Funky with func_odbc: Hot-Desking”). func_odbc is a
powerful tool for the Asterisk administrator, providing the ability to
build a static dialplan using data that is dynamic in nature. See Chapter 16, Relational Database Integration for more information about how to integrate
Asterisk with a database, and the functionality it provides.
We’re also quite fond of the
func_curl module, which provides integration with web
services over HTTP directly from the dialplan.
With the data abstracted from Asterisk directly, we will now have an easier time moving toward a system that is getting ready to be clustered. We can use something like Linux-HA (http://www.linux-ha.org/wiki/Main_Page) to provide automatic failover between systems. While in the event of a failure the calls on the system that failed will be lost, the failover will take only moments (less than a second) to be detected, and the system will appear to its users to be immediately available again. In this configuration, since our data is abstracted outside of Asterisk, we can use applications such as unison (http://www.cis.upenn.edu/~bcpierce/unison/) or rsync to keep the configuration files synchronized between the primary and the backup system. We could also use subversion or git to track changes to the configuration files, making it easy to roll back changes that don’t work out.
Of course, if our database goes away due to a failure of the hardware or the software, our system will be unavailable unless it is programmed in such a way as to be able to work without the database connection. This could be accomplished either through the use of a local database that simply updates itself periodically from the primary database, or through information programmed directly into the dialplan. In most cases the functionality of the system in this mode will be simpler than when the database was available, but at least the system will not be entirely unusable.
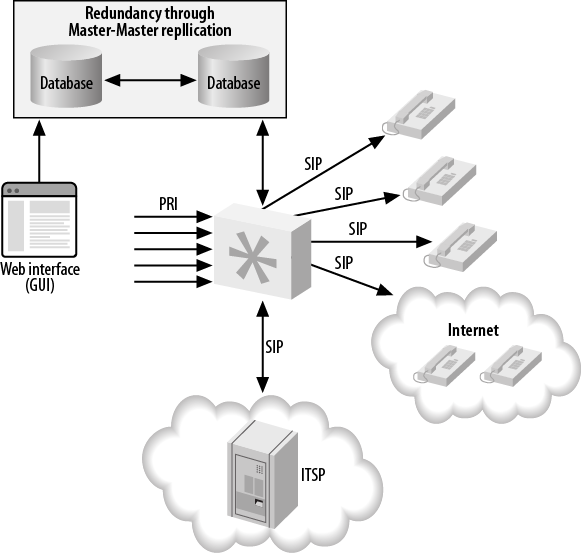
A better solution would be to use a replicated database, which allows data written to one database server to be written to another server at the same time. Asterisk can then fail over to the other database automatically if the primary server becomes unavailable.
Using a replicated database provides some redundancy in the backend to help limit the amount of downtime callers and agents experience if a database failure occurs. A master-master database configuration is required so that data can be written to either database and be automatically replicated to the other system, ensuring that we have an exact copy of the data on two physical machines. Another advantage to this approach is that a single system no longer needs to handle all the transactions to the database; the load can be divided among the servers. Figure 22.5, “Asterisk database integration, distributed database” illustrates this distributed design.
Note
We’ve used MySQL master-master replication before, and it works quite well. It also isn’t all that difficult to set up, and several tutorials exist on the Internet. Other database systems will likely contain this functionality as well, especially if you’re using a commercial system such as Oracle or MS SQL.
Failover can be done natively in Asterisk, as
res_odbc and func_odbc do contain
configuration options that allow you to specify multiple databases. In
res_odbc, you can specify the preferred order for
database connections in case one fails. In func_odbc,
you can even specify different servers for reading data and writing data
through the dialplan functions you create. All of this flexibility
allows you to provide a system that works well for your business.
External programs can also be used for controlling failover between systems. The pen application (http://siag.nu/pen/) is a load balancer for simple TCP applications such as HTTP or SMTP, which allows several servers to appear as one. This means Asterisk only needs to be configured to connect to a single IP address (or hostname); the pen application will take care of controlling which server gets used for each request.